
Kay Pacha: a Telegram Weather Chatbot using OpenAI and Open Weather Map APIs
Have you ever tried to ask Chat-GPT about the current weather in your city? Most of the time it answers something like: “It’s impossible for me to give you real time information” and it is because the OpenAI’s models don’t have access to real time information. It only knows the data which was used to train it. Here, I’m going to show you how you can create a Telegram chatbot to ask about today’s weather in any part of the world consuming OpenAI and Open Weather Map APIs.

In Inca mythology, Kay Pacha is defined as the earthly world where human beings lived their lives. It’s a simple usecase of how we can use the OpenAI API to create a Telegram chatbot to give you the current weather in any location worldwide. It additionally uses the Open Weather Map API to obtain real time information.
In order to avoid repeating the APIs name, I will follow these abreviations:
- OpenAI API: OAI
- Open Weather Map API: OWM
Additionally, the code of this demo can be found in my GitHub repository here.
Prerequisites
Before starting, you need to get your API’s keys that will be used to consume data from OWM, to send and receive data from OAI and to interact with Telegram.
These keys must be kept secret and you should be careful to not adding them to you code repository. That’s why a best practice is to handle them as local environment variables.
In MacOS, you can add them to your ~/.bash_profile or ~/.zshrc files. You can use the nano ~/.bash_profile command to edit this file and copy paste your keys at the end of the file such as:
#~/.bash_profile file
# openai key
export OPENAI_API_KEY='sk-SmKIcS...'
# openweathermap
export OPEN_WEATHER_KEY='a432c...'
# telegram api
export TELEGRAM_API_KEY='677...:AAEM...'
Don’t forget to source it with the command source ~/.bash_profile or restart the terminal. You can verify that your keys can be recognized using the command echo:
$ echo $OPEN_WEATHER_KEY
sk-SmKIcS...
High-level Architecture
This program has 4 main components:
- Weather App which orchestrates the different components making API calls to the OAI and OWM services
- OpenAI Servers: we use its
gpt-3.5-turbomodel as our conversational agent. - Open Weather Map Servers which is a third party service that provides weather information
- Telegram Bot which serves as the main interface between the user and our app
This is how this program works:
-
The user will interact with a Telegram Bot asking for some weather information.
-
The Telegram Bot will send the user’s message to OAI via our weather app using a Rest API request and will receive an answer. This answer may contain either of these two:
-
A response to the user message in which case it will be sent it back to the user via our Telegram Bot
-
An alert to inform our app that OAI has collected all the information needed to retrieve weather information such as the city, country, and units (celsius or farengheit) from our user in which case:
-
it will send another request to OAI to retrieve the latitude and longitud coordinates (lat-long) from the city and country given by the user
-
it will send these lat-long coordinates to OWM and retrieve weather information
-
It will form a message based on OWM json response and answer back to the user via the Telegram Bot adding this message to the OAI context
-
Continue the conversation
-
-
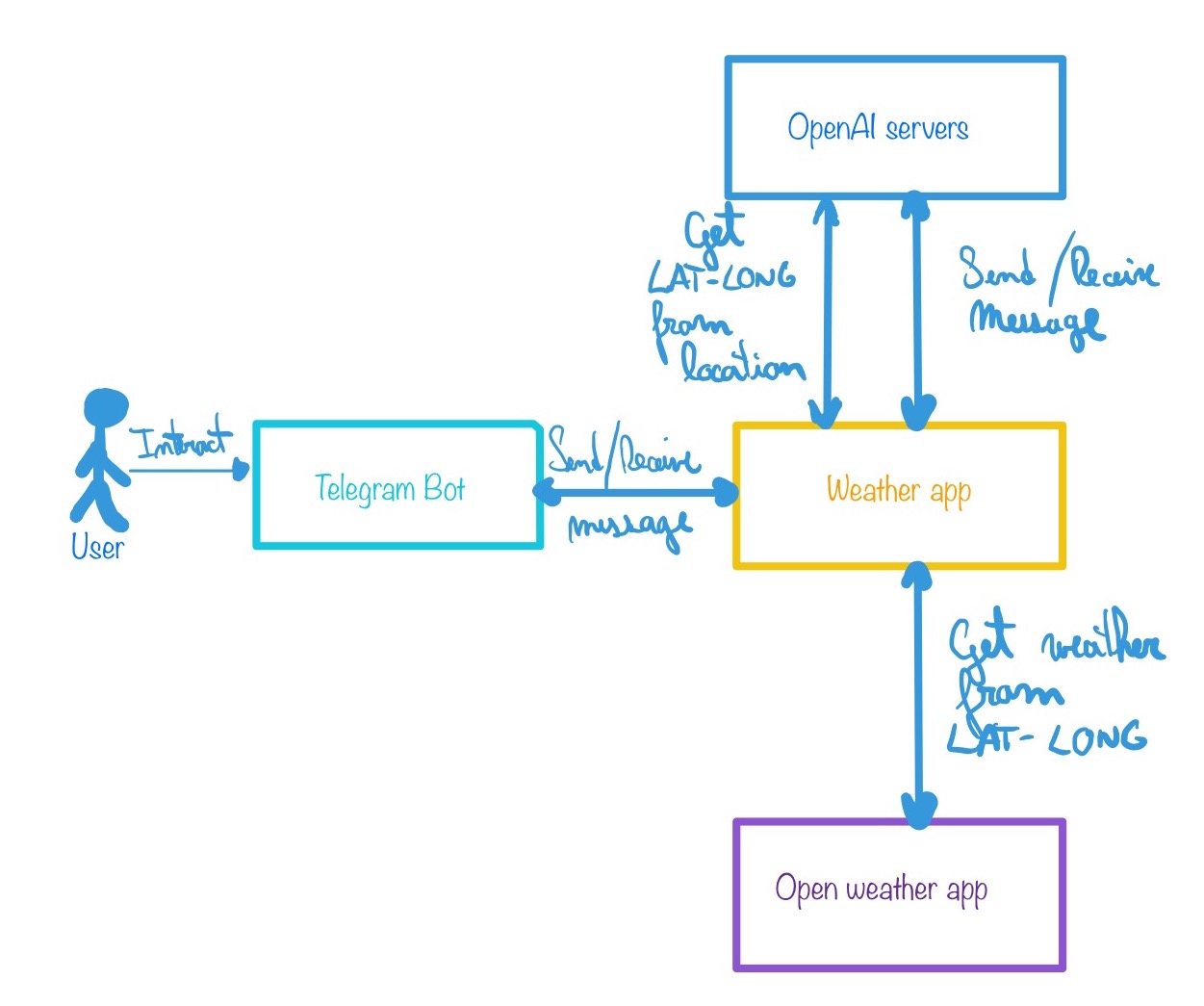
It’s importat to note that OWM expects lat-long coordinates instead of a location (city, country). It wouldn’t be very user friendly to ask for lat-long directly so instead the fully potential of LLMs is used again here to ask OAI to translate a location to lat-long coordinates using a prompt.
Also, note that OAI can be instructed to keep talking with the user until it collects a few parameters needed (in this case: city, country, and units) to execute an internal function get_current_weather(). Once these parameters are collected OAI sends an alert inside the json response with the function name to execute and the value of the parameters. I will show you how you can execute your own functions later on.
This project has the following important classes:
OpenAIChatbot: It contains the principal object that serves as an orchestrator and it depends on theWeatherAPI,ChatAssistant, andLatLonAssistantclasses. It processes user messages and get an answer back.WeatherAPI: It makes a call to the OWM API to get the current weather given a location.ChatAssistant: It follows a conversation with the user through the OAI API.LatLonAssistant: It converts location to lat-long coordinates through the OAI API.
There are two main files, one to execute the bot in a command line and another to execute it via Telegram:
main_telegram.pymain.py
OpenAI LLM Models
There are many LLM models belonging to OpenAI that you can use in a plug-and-play fashion via an API call.
Thus, to create a chatbot you should use a chat completion model. By now, these are the compatible models:
- gpt-4
- gpt-4-turbo-preview
- gpt-4-vision-preview
- gpt-4-32k
- gpt-3.5-turbo
- gpt-3.5-turbo-16k
- fine-tunned versions of gpt-3.5-turbo
Every model has its own context window, price and usage limite so I’m not going to enter into too much detail now.
The model that we’ll use is the gpt-3.5-turbo that has a limit of 60,000 tokens per minute (TPM), 500 requests per minute (RPM), and 10,000 requests per day (RPD) under the tier 1. It has a cost of $0.50/1M input tokens and $1.50/1M output tokens and it has a 16K-token context window.
Context Window
Conext window refers to the maximum amount of tokens you can send in one API call to give the LLM some context before answering. Just to have an idea a page with a lot of text and small font might have approximately 800 tokens so you can send roughly speaking 20 pages of text to give some context to OAI LLM. Current models, such as GPT-4 supports 128K token context which is about 160 pages (half a book!) which is a lot of context already.
But what do we mean exactly by “context”?
Context refers to the surrounding words or phrases that influence the interpretation and generation of text. The model uses the context to predict the most probable next word or sequence of words. When we have a conversation with gpt-3.5-turbo, we need to provide the entire conversation history (up to 16K tokens approx.) so the model can “remember” what they were talking about before with the user and generate an appropiate answer. All of these words are converted to tokens and sent to the model via the API call.
Chat Roles
A role helps LLMs to know who is sending the message and how it should interact with the user.
OpenAI models define three roles:
- System: its content tells LLM how to act and what to do.
- Assistant: its content has a message sent by the LLM.
- User: its content has a message sent by the user.
So we can have an interaction with an OAI model as follows:
- system: act as a very professional data scientist and answer only data science questions.
- user: Hi
- assistant: Hi, I’m a very professional data scientist and I’m here to answer any question you might have regarding data science
- user: Could you please tell me how random forest algorithm works?
- assistant: Sure! Random forest is an algorithm….
You can note that system contains an instrution about how we are expecting the LLM to act, user is what the user is saying and assistant contains a message that was returned by the LLM model.
OpenAI Chat Completions
If you want to create chatbots using the OpenAI API, you need to be familiar with the chat completions request which it looks as follows:
from openai import OpenAI
client = OpenAI()
completion = client.chat.completions.create(
model="gpt-3.5-turbo",
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Hello!"}
],
max_tokens=500,
temperature=0.2
)
print(completion.choices[0].message)
And expect a response such as:
{
"id": "chatcmpl-123",
"object": "chat.completion",
"created": 1677652288,
"model": "gpt-3.5-turbo-0125",
"system_fingerprint": "fp_44709d6fcb",
"choices": [{
"index": 0,
"message": {
"role": "assistant",
"content": "\n\nHello there, how may I assist you today?",
},
"logprobs": null,
"finish_reason": "stop"
}],
"usage": {
"prompt_tokens": 9,
"completion_tokens": 12,
"total_tokens": 21
}
}
OpenAI will search internally for an environment variable called OPENAI_API_KEY that contains your secret token to communicate with their servers.
The client.chat.completions.create method expects to provide a model and the chat history together with the system instruction. Additionally, you can send the max_tokens parametter that tells the model to limit their response to 500 tokens and the temperature that is a float value between 0 and 2. Higher values like 0.8 will make the output more random, while lower values like 0.2 will make it more focused and deterministic. Take a look to a complete list of parameters here.
The response contains the LLM response to the user inside the message attribute.
If you want to integrate this code into yours you need to save the chat history somewhere. For instance, you can use an array called messages and append the user and assistant responses:
class ChatAssistant():
def __init__(self, role, model, tools=[]):
self.client = OpenAI()
self.messages = []
self.tools = tools
self.max_tokens = 180
self.temperature = 0.2
self._set_role(role)
self._set_model(model)
...
def send_message_wo_func_exec(self, message) -> str:
self.messages.append({
"role":"user",
"content": message
})
completion = self.client.chat.completions.create(
model=self.model,
messages=self.messages,
max_tokens=self.max_tokens,
temperature=self.temperature
)
assitant_message = completion.choices[0].message
self.messages.append(assitant_message)
return assitant_message.content
Function executions
OAI models can be instructed to send you an alert event to execute some custom functions after a conversation with the user. The conversational model keeps talking with the user until it gets what they need to execute the function, and once it collects all this information, it responds with a function-call event.
Let’s say that you have a get_current_weather(location) function with a single parameter: the location where to get the current weather from. You want the model to talk to the user and ask it about a location. Once the model recognizes that the user has provided a location, it sends a function-call event with the function name and location parameter values so you can proceed to execute it.
To do so, we only need to add an extra parameter to the client.chat.completions.create method called tools which contains a definition about what parameters it needs, what these parameters are, and what the function name is.
class OpenAIChatbot():
def __init__(self) -> None:
...
self.tools = [
{
"type": "function",
"function": {
"name": "get_current_weather",
"description": "Get the current weather in a given location based on city and country",
"parameters": {
"type": "object",
"properties": {
"location": {
"type": "string",
"description": "Get the current weather in a given location based on city and country",
},
"units": {
"type": "string",
"enum": ["celsius", "fahrenheit"],
"description": "The temperature unit to use. Infer this from the users' location",
},
},
"required": ["location", "units"],
},
}
}
]
...
The tools property contain a json that will be sent to OAI later on. It contains the name of the function it should alert us to execute get_current_weather together with its description: Get the current weather in a given location based on city and country, and the parameters needed such as the location and the units.
This tools property is then passed through the client.chat.completions.create method as follows:
class ChatAssistant():
...
def send_message(self, message) -> MessageType:
self.messages.append({
"role":"user",
"content": message
})
completion = self.client.chat.completions.create(
model=self.model,
messages=self.messages,
max_tokens=self.max_tokens,
temperature=self.temperature,
tools=self.tools # <------ send it here
)
return self._answer(completion.choices[0])
...
The function-call event we can get from OpenAI once it collects all the required arguments from the conversation is similar to this one:
{
"id": "chatcmpl-abc123",
"object": "chat.completion",
"created": 1699896916,
"model": "gpt-3.5-turbo-0125",
"choices": [
{
"index": 0,
"message": {
"role": "assistant",
"content": null,
"tool_calls": [
{
"id": "call_abc123",
"type": "function",
"function": {
"name": "get_current_weather",
"arguments": "{\n\"location\": \"Boston, MA\"\n,\n\"units\": \"celsius\"\n}"
}
}
]
},
"logprobs": null,
"finish_reason": "tool_calls"
}
],
"usage": {
"prompt_tokens": 82,
"completion_tokens": 17,
"total_tokens": 99
}
}
Note that the message content is null cause this is not an assitant message but an alert to execute a function. We differentiate an assistant from an alert response using the finish_reason attribute. If it’s an indicator to execute a function it will have the tool_calls value; otherwise, it will have the stop value.
This request also has the function name to execute together with the arguments infered from the conversation with the user. In this case the location is Boston, MA and the units are celsius so the user wants to know the weather in that location using that unit.
If we want to differentiate an assitant from an alert response, we can use the following code:
class ChatAssistant():
...
def _answer(self, choice) -> MessageType:
if choice.finish_reason == 'tool_calls':
function_to_call = choice.message.tool_calls[0].function
return MessageType(
type=Type.FUNC_CALL,
content=function_to_call)
else:
assistant_message = choice.message
self.messages.append(assistant_message)
return MessageType(
type=Type.MESSAGE,
content=assistant_message.content)
...
It returns an object called MessageType that contains either the function call or the message.
We can then execute the custom function and add it to the context if need it or we can continue the chat as follows:
class OpenAIChatbot():
def __init__(self) -> None:
...
self.weatherAPI = WeatherAPI()
self.chat_assistant = ChatAssistant(role=self.role, model=self.model, tools=self.tools)
self.lat_lon_assistant = LatLonAssistant(self.model)
...
def interact(self, msg):
message = self.chat_assistant.send_message(msg)
answer_from_api = message.content
if message.type == Type.FUNC_CALL:
func = message.content
if func.name == 'get_current_weather':
arg = json.loads(func.arguments)
answer = self._get_current_weather(arg["location"], arg["units"])
answer_from_api = answer
self.chat_assistant.add_context_as_assistant(answer_from_api)
return ' '.join(answer_from_api.split())
Where msg is the message sent by the user and self._get_current_weather is an internal function that will give us the current weather in natural language through the OWM and OAI APIs.
class OpenAIChatbot():
...
def _get_weather_from_json(self, weather, units, location):
return f'Current weather in {location} is {weather["current"]["temp"]} {units} degrees, with a \
feels like sensation about {weather["current"]["feels_like"]} {units} degrees. Humidity of \
{weather["current"]["humidity"]}%. Meteo says: {weather["current"]["weather"][0]["description"]}.'
def _get_current_weather(self, location, units):
units_to_send = 'imperial'
if units == 'celsius':
units_to_send = 'metric'
(lat,lon) = self.lat_lon_assistant.get_lat_long(location=location)
if (lat == 0 and lon == 0):
return 'It was not possible to find the location. Try again with another.'
weather = self.weatherAPI.get_weather(lat=lat, long=lon, units=units_to_send)
return self._get_weather_from_json(weather=weather,units=units, location=location)
...
This function receives the location and the units, it sends a request to OAI to translate that location into lat-long coordinates using the lat_lon_assistant object. If the values received are different than 0, it means that OAI answered with a valid lat-long coordinate that will be sent latter on to OWM using the weatherAPI object. Once the response arrives in JSON format, it will be decoded and formatted in a human readable object within the _get_weather_from_json function.
Prompts used
Two prompts were used: one for the Chat Assistant and another one for the Lat-Long Assistant.
Chat Assistant
This is the system prompt used that helps OpenAI to keep talking until it gets all the information it needs to execute a function:
You are an assistant that gives the current weather anywhere in the world based on city and country.
If the user asks you another question about another topic, you have to answer that you are only an assistant who gives the current weather and nothing more.
Don't ask what city you are in, rather ask what city you would like to know the weather for.
Don't make assumptions about what values to insert into functions.
Please request clarification if a user's request is ambiguous regarding the city and country provided. Do not make up with random climate values.
Lat-Long Assistant
This is the prompt used to get the latitude and longitude coordinates given a location:
You are going to receive an address and your function is return the earth coordinates of this address: the latitude and longitude of said city/country in JSON format. For example, if you receive: Cochabamba, Bolivia you should return:
{
"latitude": -17.3895,
"longitude": -66.1568
}
Do not add any extra information. In case you don't know these coordinates, you can return a JSON like this:
{
"latitude": 0,
"longitude": 0
}
Conclusion
OpenAI API is a powerful tool that can be used to execute local functions using natural language queries. It may be used in many other escenarios such as an API call, function executions, SQL requests, Store Procedure executions, search engines, etc. This functionality in OpenAI is key to use common human language to make complex tasks and thus extend our system’s funcionality. Additionally, the OpenAI API is very intuitive to use and to configure.
Additionally, it’s important to mention that we should use this API responsibly. We shouldn’t release anything to production before doing many, many (and I’m serious about this, many) tests. If your application ends up doing something that OpenAI doesn’t like (check its usage policies before releasing something), it might move your token to an unauthorized tokens list and put yourself in the spotlight or even worst, it might ban your account.
Another aspect which is important is that we can implement complete code funcionallities with a simple OAI API call such as translating location to lat-long coordinates, extracting key information, performing sentiment analysis, text classification, tags extraction, etc… which might save us a lot of time instead of creating custom code or training our own general-purpose models.
Finally, experimenting with the API is not very expensive. I’ve put 10 $us to my account and after many tests and interactions I’ve only spent less than 2 $us which is great. However, if your application scales it might cost you a lot of money so be careful.
Further Improvemens
This project was created with the aim to give you some insights about OpenAI API usage and thus it is far from being a ready-to-prod application. Some improvements should be done so it can be more robust:
- This demo is a POC only so there is a lot of room for improvement regarding the quality of the code (SOLID, design patterns implementation, DRY, etc…)
- Add some unit tests and lighting tools that performs code smells
- Implement CI/CD pipelines
- Document the code
Excercises
If you want to practice, I challenge you to extend this project to do the following:
- Get the current weather given two or more locations. You should take a look to parallel function calling functionality here. For instance, the interaction could be as follows:
- user: I'd like to know the weather in Oslo, Norway and Paris, France
- assistant: Sure! The weather in Oslo is -3 celsius degrees. The weather in Paris is 1 celsius degree.
- Create a new function called
get_weather_for_following_days(location, units, days=5)that will get the weather prediction forcasting for the nextx days. This function will be executed thanks to a new alert configured within thetoolsattribute. - Create a bot based on this one that will give you real-time flight price information using an already existing API such as the Skyscanner API.
Last but not least
If you enjoyed this post, please star the GitHub repo and share this blog with your collegues. Thanks!